US - EN
Enabling the "Data-Driven Organization” - Making the Most of Your Data: The Importance of Metadata Management and Business Intelligence
In my three prior blog posts in this four-part series, I discussed the importance of establishing executive sponsorship, stakeholder participation, effective business processes, and tools for Data Governance and Master Data Management (MDM). I also emphasized the need to have the right “data plumbing” in place to integrate data from disparate source systems, standardize that data, and make it easily consumable by your information stakeholders.
This final blog will address the two Enterprise Information Management (EIM) disciplines that turn data “raw materials” into an information “product”—Metadata Management and Business Intelligence.
Metadata Management
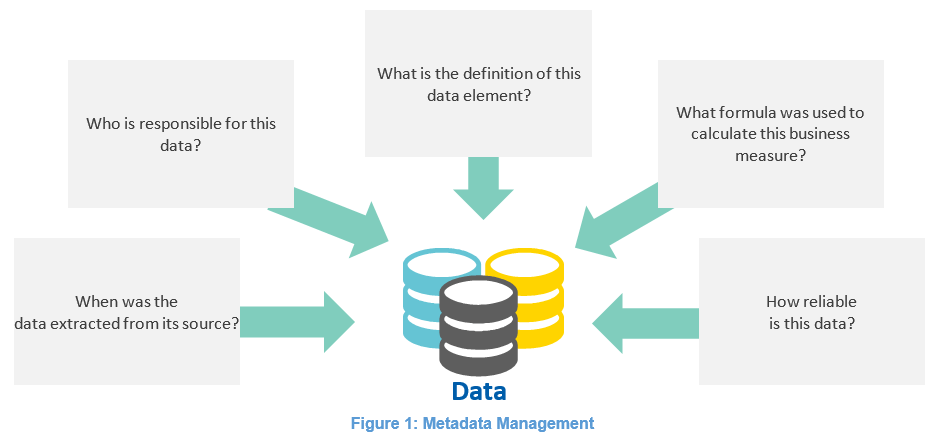
Metadata is often defined as “data about data,” although I personally don’t find this definition very helpful. When I discuss the concept of metadata with clients, I often ask questions such as:
- Do you have questions about the definition of a Key Performance Indicator (KPI) or other business-defined measures when you’re looking at an executive dashboard or a report?
- Do you ever question the formula that was used to calculate the KPI or measure, or wonder where the data came from?
- Do you trust the quality of your KPIs? Would it be helpful to have each KPI flagged as “high quality,” “somewhat suspect,” or “use at your own risk?”
Metadata Management solutions help address the underlying issues within these questions by providing information stakeholders and consumers with easy access to data definitions, formulas, and other pertinent information about their data.
For many years, data dictionaries have been considered a metadata repository by many organizations. A data dictionary, as defined in the IBM Dictionary of Computing, is a “centralized repository of information about data, such as meaning, relationships to other data, origin, usage and format.” However, a robust metadata management solution provides much more functionality than that. It is more than just an Excel spreadsheet or a web page on the organization’s web portal that provides access to data definitions. For example, best-of-breed metadata management solutions provide “connectors” that allow business and technical metadata to be imported from multiple applications and also provides data modeling and data acquisition (e.g., Extraction/Transformation/Load or ETL) tools to help them manage, and make sense of, this disparate data.
More importantly, metadata management solutions provide impact analysis capabilities that identify all components, such as database tables, reports, or dashboards, that can be affected by a potential database change. An even more valuable feature offered by these solutions is data lineage, which provides a graphical depiction of where the data came from and what changes were made to it before it ended up on the executive dashboard or report. This data transparency can dramatically improve user confidence in the final presented information.
Business Intelligence
The last EIM discipline to be addressed in this blog series, Business Intelligence (BI), is the one that is most visible—and arguably most important—to inform stakeholders and consumers. The wide variety of products used for data visualization, drill-down analytics, ad hoc queries, predictive modeling, and data mining are collectively known as BI tools. Rather than providing a comparative analysis of these various tools, I would instead like to discuss two very different analytic methodologies that are enabled by BI: Online Analytical Processing (OLAP) and Data Mining.
OLAP is by far the most common analytic approach used to perform BI activities that prove or disprove an existing hypothesis. For example, when an executive dashboard highlights a KPI in red, yellow, or green, the developer of that dashboard has applied a business rule to indicate to the user that a condition has been met that might require further investigation. For example, if a hospital executive sees the Readmission Rate KPI highlighted red, this indicates that the calculated rate is higher than anticipated and thus a potentially serious problem exists. The hypothesis, or business rule, is then investigated to determine the root cause. This investigative analysis is usually done by performing some sort of “drill-down” query to obtain additional detail. The key point here is that this type of analysis is based on a pre-existing business rule or hypothesis regarding the information.
Data mining uses very different types of tools to develop a hypothesis based upon patterns contained in the data versus proving/disproving an existing one. In other words, it uncovers hidden value or “nuggets” of information that the human mind might not otherwise have found. An example of my experience with true data mining found a high correlation between motorcycle owners and employees who had filed worker compensation claims. Once a hypothesis like this is developed via data mining, it can then be validated or invalidated by OLAP analysis, the first methodology we discussed. The important takeaway is that no one developed this hypothesis, but rather it was identified by a Data Mining tool.
Throughout this series, we’ve defined a data-driven organization as one that uses dashboard-enabled performance management techniques to improve business insights and information transparency. This requires timely access to clean, consistent, reliable, and most importantly, actionable information to the organization's decision-makers. Simply put, data-driven organizations are fully committed to the management of information as an invaluable strategic corporate asset. Actionable information provided to leadership allows the organization to thrive in an increasingly constrained and competitive fee-for-value environment. Rather than “driving by looking in the rearview mirror” with stale information, leaders in a data-driven organization can make timely, proactive decisions regarding access to care, costs of care, and quality of care, thus fostering greater stability and growth while better serving our communities.
Looking for a job?
We’re always on the lookout for great people who share our commitment to enabling our clients’ transformations.
Social media cookies must be enabled to allow sharing over social networks.